November 14, 2017
Character Assassination: Fun and Games with Unicode
Written by
TrustedSec
Penetration Testing
Security Testing & Analysis

Why this subject? I love Unicode, and I even adopted a character (I’ll let you guess which one). Lots of research has been done on Unicode security issues, but not many people talk about it. Unicode was created to provide an expandable character set to encompass more languages than the standard Latin alphabet can express. Complexity is the damnable enemy of security, but human language is complex so what can you do? I’m hoping this short article will act as a setup for future research on the subject of Unicode security, by giving you some basic information, and will encourage others who are better at exploit development than me to look into it.
 If Windows-1252 is confused for ISO 8859-1, you get � for these characters. This regularly causes me fits when I’m working with metadata for con videos. It also sometimes makes copying and pasting commands in tutorials a pain if the document editor decides to replace underscores and quotes. Related trivia: ever see a random 'J' in an email? That’s because some Microsoft products express a ? as a J from the Wingdings font.
Anyway, back to Unicode’s history. Joe Becker (Xerox), Lee Collins, and Mark Davis (Apple) started working on Unicode in 1987 to make a more flexible character encoding system. Unicode version 1.0.0 was released in October 1991. Unicode started as a 16-bit character model (0x0-0xFFFF), with the first 256 code points being the same as ISO-8859-1 (Latin-1).
Each character has a code point associated with it:
A = U+0041 $=U+0024 U+265E=♞
This has since been expanded, so that Unicode has points from 0x0 to 0x10FFFF (1,114,112 points in decimal - 24 bits), though support for versions of Unicode varies. For example, Unicode 10.0 was approved June 20, 2017, but likely is not supported on your platform yet or this ? (U+1F994) would look like a hedgehog. While Unicode is highly expandable, most points you will use will likely be in the Basic Multilingual Plane (BMP) represented as U+0000 to U+FFFF.
If Windows-1252 is confused for ISO 8859-1, you get � for these characters. This regularly causes me fits when I’m working with metadata for con videos. It also sometimes makes copying and pasting commands in tutorials a pain if the document editor decides to replace underscores and quotes. Related trivia: ever see a random 'J' in an email? That’s because some Microsoft products express a ? as a J from the Wingdings font.
Anyway, back to Unicode’s history. Joe Becker (Xerox), Lee Collins, and Mark Davis (Apple) started working on Unicode in 1987 to make a more flexible character encoding system. Unicode version 1.0.0 was released in October 1991. Unicode started as a 16-bit character model (0x0-0xFFFF), with the first 256 code points being the same as ISO-8859-1 (Latin-1).
Each character has a code point associated with it:
A = U+0041 $=U+0024 U+265E=♞
This has since been expanded, so that Unicode has points from 0x0 to 0x10FFFF (1,114,112 points in decimal - 24 bits), though support for versions of Unicode varies. For example, Unicode 10.0 was approved June 20, 2017, but likely is not supported on your platform yet or this ? (U+1F994) would look like a hedgehog. While Unicode is highly expandable, most points you will use will likely be in the Basic Multilingual Plane (BMP) represented as U+0000 to U+FFFF.
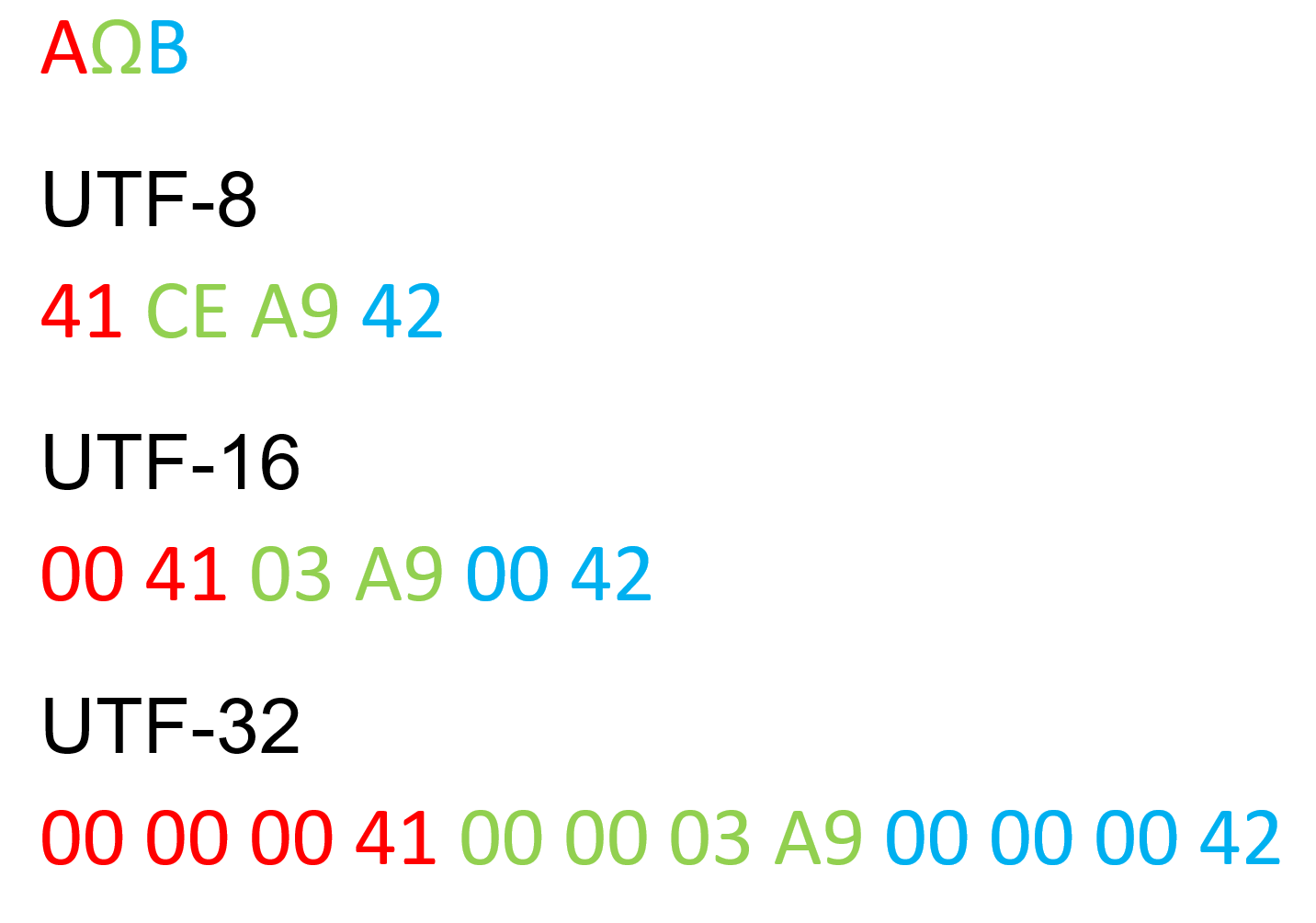 The UTF-8 is somewhat confusing, so I hope this table from Wikipedia helps:
The UTF-8 is somewhat confusing, so I hope this table from Wikipedia helps:
 UTF-16 Encoding gets even more complex. In UTF-16, U+10000 to U+10FFFF use surrogate pairs in range 0xD800 to 0xD8FF. Here are the rough encoding steps, based on http://en.wikipedia.org/wiki/UTF-16:
UTF-16 Encoding gets even more complex. In UTF-16, U+10000 to U+10FFFF use surrogate pairs in range 0xD800 to 0xD8FF. Here are the rough encoding steps, based on http://en.wikipedia.org/wiki/UTF-16:
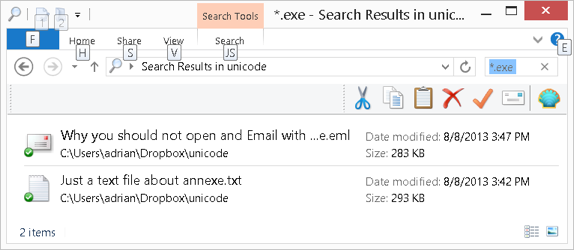 In the example above, the “Just a text file about annexe.txt” is really “Just a text file about ann U+202E txt.exe”. This could make a dropped thumbdrive scenario look more plausible.
In the example above, the “Just a text file about annexe.txt” is really “Just a text file about ann U+202E txt.exe”. This could make a dropped thumbdrive scenario look more plausible.
Unicode History
Most people who have gone through a programming class know about ASCII (American Standard Code for Information Interchange) or extended ASCII, but Unicode is more complex than just 128 or 256 characters mapped to numerical values. ASCII is 7-bits in length and just 96 printable characters, but an 8th bit was added to make other standards: Extended ASCII ISO/IEC 8859 ISO/IEC 8859 uses the last bit to add another 96+ characters, as well as control characters. You have to specify a code page/language in order to determine which character set to which those 96 will belong. This was okay for a bit, but was still not enough to encompass all languages and did not allow for several of the mixed languages. The goal was to represent all the characters as unique code points, and not get confused amongst languages or what characters should be used (as often happens with the “smart quote”, hyphens, and so on within Windows). Actually, let me side step into a rant and say Ihate Smart Quotes! “Smart” quotes are "Not so smart" �Smart when dumb� Why? When Microsoft extended ISO 8859-1, they made some control characters in the 80 to 9F range printable for Windows-1252
If Windows-1252 is confused for ISO 8859-1, you get � for these characters. This regularly causes me fits when I’m working with metadata for con videos. It also sometimes makes copying and pasting commands in tutorials a pain if the document editor decides to replace underscores and quotes. Related trivia: ever see a random 'J' in an email? That’s because some Microsoft products express a ? as a J from the Wingdings font.
Anyway, back to Unicode’s history. Joe Becker (Xerox), Lee Collins, and Mark Davis (Apple) started working on Unicode in 1987 to make a more flexible character encoding system. Unicode version 1.0.0 was released in October 1991. Unicode started as a 16-bit character model (0x0-0xFFFF), with the first 256 code points being the same as ISO-8859-1 (Latin-1).
Each character has a code point associated with it:
A = U+0041 $=U+0024 U+265E=♞
This has since been expanded, so that Unicode has points from 0x0 to 0x10FFFF (1,114,112 points in decimal - 24 bits), though support for versions of Unicode varies. For example, Unicode 10.0 was approved June 20, 2017, but likely is not supported on your platform yet or this ? (U+1F994) would look like a hedgehog. While Unicode is highly expandable, most points you will use will likely be in the Basic Multilingual Plane (BMP) represented as U+0000 to U+FFFF.
Encodings
There are several Unicode encoding formats and this is where a lot of the complexity is derived. UTF-8 (UCS Transformation Format 8-bit) is meant to be backward compatible with ASCII, so the first 256 characters are the same as ISO-8859-1. Higher characters are encoded using more than one byte by adding unused surrogate pairs in range 0xD800 to 0xD8FF. The advantage of UTF-8 is if an application was only written for ASCII, it will still understand those characters. UCS-2 started off as just a 16 bit representation of the character's code point, but was superseded by UTF-16 (Unicode Transformation Format 16-bit), which uses a surrogate pairs system similar to UTF-8. UTF-32 (Unicode Transformation Format 32-bit) uses a straight one-to-one correlation between the code point and a 32-bit number. This begs the question, how does software know what encoding is being used? The answer is BOM (Byte Order Marks): UTF-8 prepends EFBBBF to data. UTF-16 prepends FEFF Unicode for Big Endian and FFFE for Little Endian. UTF-32 generally does not use one. Here are some encoding examples. Let’s say we want to encode the string: AΩB (capital A, Omega, capital B) A = 41h in ASCII, so is located at codepoint U+0041, Omega is at U+03A9 (not to be confused with 213d which is Omega in some extended ASCIIs) and B is at U+0042. This gives the following byte encodings:
The UTF-8 is somewhat confusing, so I hope this table from Wikipedia helps:
UTF-16 Encoding gets even more complex. In UTF-16, U+10000 to U+10FFFF use surrogate pairs in range 0xD800 to 0xD8FF. Here are the rough encoding steps, based on http://en.wikipedia.org/wiki/UTF-16:
- 0x10000 is subtracted from the code point, leaving a 20-bit number in the range 0x0 to.0xFFFFF.
- The upper ten bits (a number in the range 0x0 to 0x3FF) are added to 0xD800 to give the first code unit or lead surrogate, which will be in the range 0xD800 to 0xDBFF.
- The lower ten bits (also in the range 0x0 to 0x3FF) are added to 0xDC00 to give the second code unit or trail surrogate, which will be in the range 0xDC00 to 0xDFFF (previous versions of the Unicode Standard referred to these as low surrogates).
Homoglyph/Visual Attacks
This is a major class of attack that people thinking of security issues with Unicode have been playing with for years. A homoglyph is a symbol that appears to be the same or very similar to another symbol. By extension, a homograph is a word that looks the same as another word. Homoglyphs (look-alike characters) can be used to make up homographs (look-alike words). If we were to be pedantic, this is not quite technically correct in a language sense, as the different characters make the word, not really be the same spelling. An example of a homoglyph most would be familiar with is the letter O and the number 0. Depending on the font used, they may be hard to distinguish from one another. The letters l (lower case L) and I (uppercase i) are another common example. Where it becomes even more interesting are the places in Unicode where very similar characters exist from different languages. Languages that use characters which look similar to the normal Latin alphabet with diacritic accents, letter-like symbols and other useable homoglyphs pop up with great regularity, some seeming to be almost exact duplicates of the same symbol. Cyrillic script is a common example, possessing very close homoglyphs for a, c, e, o, p, x, and y. Even the Latin alphabet appears twice in Unicode. The characters: !"$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ are represented in both the U+0021-007E (Basic Latin) and the U+FF01-FF5E (Full width Latin) ranges of Unicode. This means changing from one encoding for a given Latin character to the other is as easy as adding the decimal value 65248 to the lower range versions. Depending on the font used, mixing character families this way may cause a “Ransom Note” like visual effect, because the exact vertical and horizontal spacing of the characters may vary. Normal Domain Name System (DNS) entries expect standard ASCII characters. To use something like a Cyrillic character, it has to be encoded in punycode. For example: café.com = xn--caf-dma.com googlе.com = xn--googl-3we.com (е is a Cyrillic small letter ie U+0435) While the intended purpose of Internationalizing Domain Names in Applications (IDNA) is to allow for internationalized DNS labels, it can also be used to make a URL or hostname appear more legitimate than it really is. Because the Unicode representation may cause visual confusion for a user, it could provide a false sense of trust. The good news is that a lot of software and social media platforms have gotten much better at making sure homoglyphs in URLs are more obvious. I’ve written about this more extensively here: http://www.irongeek.com/i.php?page=security/out-of-character-use-of-punycode-and-homoglyph-attacks-to-obfuscate-urls-for-phishing If you want to play with homoglyph attacks I have a convenient set of tools here: http://www.irongeek.com/homoglyph-attack-generator.php Besides URLs, homoglyph attacks can be used in social media to cause confusion. Most services seem to be restrictive on characters allowed, but some homoglyphs exist in standard ASCII. For example 'dave_rel1k' and 'dave_reI1k' can be two different accounts. Another weird thing I’ve found is people using homoglyphs to confuse searches. For example, a search for a drug’s name, and a modified name with a homoglyph, return different results. Notice the difference in a Google search for mеth (e is codepoint U+0435) and meth. https://www.google.com/search?q=mеthhttps://www.google.com/search?q=meth I’m not sure exactly what the purpose of people doing this is. To confuse search engines and bypass filters I guess.Steganography
Steganography is not taken seriously by some, but it’s still fun to play with. Using a combination of homoglyphs and non-printable characters I came up with a few ways to encode hidden text. If you want to play with the encoders here is the link: http://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder Stego Examples One way to encode would be to alternate between Latin and Full-width Latin; just add/subtract 65248 decimal. Use U+205F as space: This is my cover text to use. Do you think it will work? I hope that it will. But as you see, it has a “Ransom Note” effect that gives it away. Another option is to use very close homoglyphs to encode single bits. Skip if there are no close homoglyphs, use 8 types of space like characters (U+0020, U+2004, U+2005, U+2006, U+2008, U+2009, U+202F, U+205F) to encode 3 bits each (000,001,010,011,100,101,110,111). Τhiѕ іѕ my cover tехt tο usе. Dο yοu thіnk іt wіll wοrk? I һοре that it will. Another system is to use non printable Tags in U+E0000 to U+E007F. Also easy - just add/subtract 0xE0000. This ?is ?my ?cover ?text ?to ?use. ?Do ?you ?think ?it will work? I hope that it will.Right to left?
Josh Kelley mentioned this one to me: Unicode has support for scripts that are right to left or left to right. What about left to right mixed with right to left scripts? For that, Unicode has U+202E (Right-to-Left Override) and U+202C (Pop Directional Formatting) so you can mix right to left or left to right scripts together. A thing to experiment with using these control characters to make executables look less suspicious:
In the example above, the “Just a text file about annexe.txt” is really “Just a text file about ann U+202E txt.exe”. This could make a dropped thumbdrive scenario look more plausible.