COFFLoader: Building your own in memory loader or how to run BOFs

Intro
Have you heard of the new Beacon Object File (BOF) hotness? Have you ever thought that you should be able to run those outside of Cobalt Strike? Well, if that's the case, you came to the right place. In this post, we'll go through the basic steps of understanding and building an in-memory loader for any type of format be that an Executable and Linkable Format (ELF), Mach Object file format (Mach-O), Portable Executable (PE), or Common Object File Format (COFF) files, using COFF as the example and releasing a reference implementation with beacon compatibility built in. The steps are pretty much the same and the more of these types of loaders you write, the better you get at writing them.
For this post we'll break the process down into the basic sections. These steps will be pretty similar across different executable file types with some detail changes and include understanding the file format, defining structures, parsing the format, linking/loading, and executing the loaded code.
For those who want to skip ahead, go to the resources section for the source code for this simple version. I do recommend that you actually follow along and write your own implementation, though—it's not as difficult as you might think and will provide a better understanding of how the COFF format is built.
Understanding the File Format
The first part of writing any in memory loader is to understand the structure you will be loading. In some cases, they are extremely well documented, so you can usually look them up and some even have the structures already generated for you to use. In this case, we're going to be generating everything ourselves, because if you're learning how to do this, you may need to be able to generate structures from just what's documented.
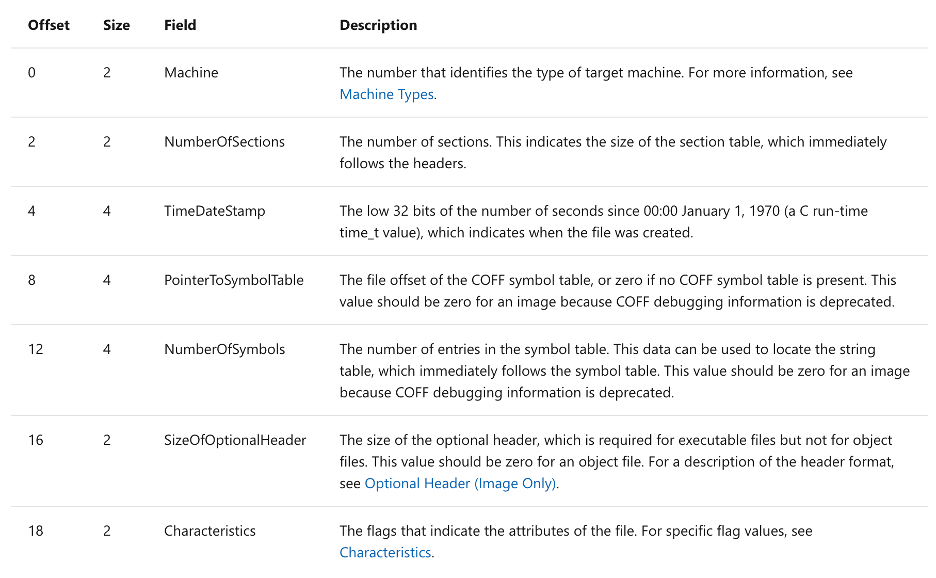
In this case, our structure is fairly well documented by Microsoft on their page https://docs.microsoft.com/en-us/windows/win32/debug/pe-format#coff-relocations-object-only. On this page, you'll see information like 'COFF File Header (Object and Image).' These definitions tell you what fields and what sizes you need the items of your structure to be. A little farther down the page, you'll see definitions of constants and what they should be defined as and definitions of flags that will be used inside your loader. While trying to understand the structures, you'll want to keep track of what’s all needed for your specific implementation—if you only need to support two (2) architectures, you may be able to get away with keeping the definitions you need down to a minimal amount. On that page, you'll find a handful of structures that you will need to build your loader.
Defining Structures
Once you have a decent understanding of the file format, it's time to define your structures. This could be done during the understanding step, but I find it easier to break these into two (2) different sections. For each file format, you'll have a header that will lay out the structure and will provide a starting point. In this case, an image of the documented structure is below.
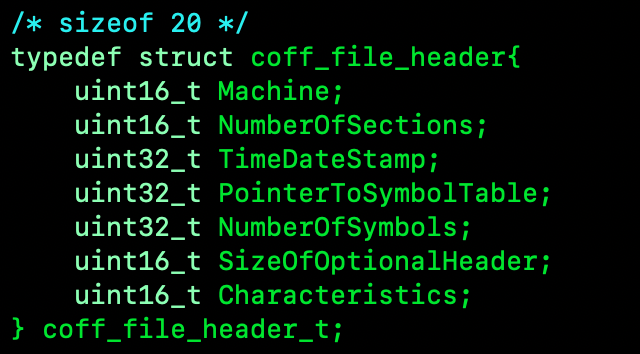
In the COFFLoader project, the structure looks like this. I’m using 'stdint.h' defined types because I’m sure of the sizes across platforms.
If you are working with another format, you may have some other structures that you need and can determine their location based on the values in the header. In the case of the COFF file format, we'll need the following structures: header, section, relocation, and symbol structures. These will be documented in the same way as the header structure on that page.
Parsing the Format
Once all that is defined, you can start actually parsing the structure. Start by setting the header pointer to the start of the read in bytes. When parsing the fields, you will get the offsets to different structures, in this case mostly the symbol pointer. The details of how to parse the format will be unique to each of the file formats, and many of them will have a few fields that can be located based on the header structures. Other structures require iterating over a list of structures by a number of entries starting from the byte following the end of the header. In the case of the COFF file format, you have both. The symbol pointer is in the header, which we can iterate over by 'NumberOfSymbols,' and directly after the header you start iterating over section structures by 'NumberOfSections'. By combining all of these pieces, you should be able to parse all the fields and print everything without any problems.
Linking/Loading
At this point, you got the format completely parsed out and should have all the details needed to actually load and execute the code. How to load and execute the code depends on how you want to allocate the memory. In our example, we will focus on just using 'VirtualAlloc' with 'PAGE_EXECUTE_READWRITE,' which is the simplest version that we can do. Various other options exist, and I'll leave those up to you to implement in your own version. When memory is allocated and you start loading, you simply copy the section's data into those locations. When loading those, you can save the offsets of the sections for use in relocations. When it's loaded in memory, you then have to handle the relocations to match your memory locations. You can do this by iterating over the sections and, inside that, iterating over the “NumberOfRelocations” for each of them.
How to handle the relocations will change on each architecture and different file formats. For the COFF relocations, Microsoft has the types documented under the 'COFF Relocations (Object Only)' section. For our case, we're only using the relocation types that I saw present in the COFF files I was testing. When everything is loaded in memory, memory relocations are done, and permissions are correct, it's time to actually execute the code. One thing I want to note though before we move onto that is that most of the 64-bit relocations are just 32-bit values, so if your allocations are farther apart than what can be represented in 4 bytes, you will want to fail out gracefully.
Executing
By the time you hit this point, most of the hard parts are behind you. Now you get to test it all out and see if it works. First, you'll need the actual location of the function you are calling. You should be able to parse the symbols and determine the address of a specified symbol based on the information in that structure along with the addresses saved when allocating the memory for your loaded COFF file. Once that is resolved, you simply have to define the function pointer and call it directly. If everything was done correctly, you should see your code loaded, executed, and returned back to the loader program. If instead you see it call the function and crash, that's OK—it just means that something isn't quite right. Review the code and keep modifying it. The problem will most likely be in the relocations since that’s the trickiest part from my point of view.
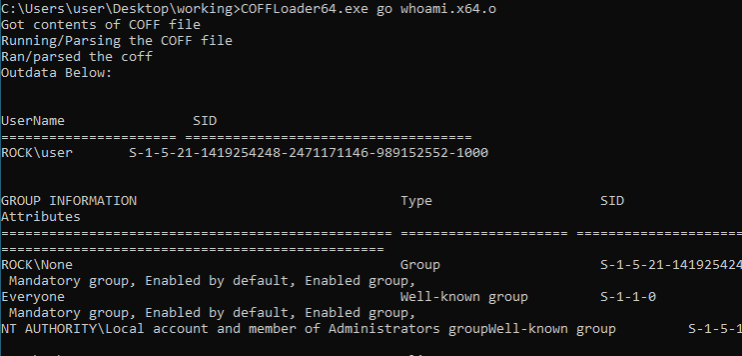
Review
Now that you have an understanding of how to approach the generic steps to build an in-memory loader for different file formats, hopefully you feel comfortable enough to take up one of these projects and implement them yourself. Below is the list of resources for you to dig into the topic more and the link to the reference loader to make a running version available to the public. I do highly recommend building your own, especially if you plan on implementing a version of it into your own agents.
Currently, the version in the repo is only suitable as a development tool to test BOFs when you don't have access to Cobalt Strike. Some future work for this could be providing a stable public version of a BOF runner library that will work across C2 frameworks, but that is beyond the scope of this blog post and this repo.
Resources
- https://github.com/trustedsec/COFFLoader
- https://docs.microsoft.com/en-us/windows/win32/debug/pe-format