Incident Response: Bring Out the Body File

An Incident Response (IR) examiner faced with a case or asked whether something 'funny' or 'bad' happened on a host will wonder if a comprehensive file listing is attainable for the system in question. Sometimes this comes in the form of a question, such as "How long has that malware been there," or "Was the file present on the system after the exploitation?" Reviews of Windows system analysis have long relied on the Master File Table ($MFT) to answer questions like these. But what is of similar value on a Linux system? The answer to that question lies in the Linux body file, which can be regarded as an unsung substitute for the $MFT when dealing with Linux analysis cases. After reading through this post, the reader should come away with some ideas and tactics to consider for their next Linux IR case. (For more about body files, please refer to: https://wiki.sleuthkit.org/index.php?title=Body_file).
As mentioned above, IR practitioners who work on Microsoft Windows cases will at some point feel that getting a file listing from the Windows host will help with their analysis. With Windows systems, this is usually easy to handle. For starters, we are assuming that the host in question has storage drives formatted in either NTFS or exFAT format, allowing the examiner to immediately obtain the $MFT file, which provides a comprehensive file listing of every file on a specific storage drive.
The $MFT is great because its information value all in one file goes beyond filenames and folder locations in which the files are present to also include essential timestamps for the files, as well as interesting attributes that aid in understanding what is going on with any file on that drive. Another thing to think about with Windows systems is that every drive has its own $MFT. If a host that you are investigating has multiple drives, you may need to collect an $MFT from each drive to have a full listing for each of those drives.
Here is an example of what could appear in an $MFT listing, using the tool MFT Explorer.
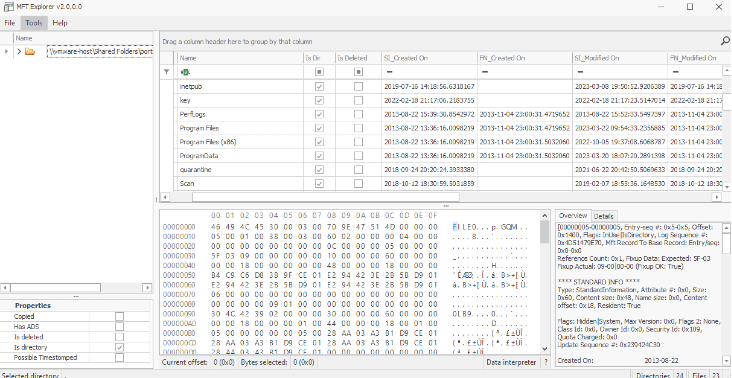
With Linux, the calculus changes somewhat. Most Linux file system formats like ext2, ext3, ext4, or xfs don’t have a single file object like the NTFS $MFT file that acts like a card catalog of all the files available to the Linux system. The Linux OS relies on different information to maintain a record of essential specific information about all files on a Linux host.
In fact, all the items in any Linux file system are regarded as files. Even a directory (folder) for organizing data is a special type of file in a Linux OS. Shortcuts that point the way to files located elsewhere in the file system have special attributes to inform the Linux OS, in essence saying, "This points to the actual location of the file content, and here is how you go retrieve it." Those are files too. Even ownership and the ability to read, write, or launch (or execute, in Linux terms) are specific attributes that are tied to each file, and that information is very helpful with IR analysis.
So, where do you retrieve that information like you would on Windows file systems? The answer usually lies in two (2) items: stat and find.
First, stat is a well-known utility for the Linux OS that comes with nearly all the file systems for the Linux platform. I have showcased the use of this powerful utility before in previous blog posts, and rightfully so, as it plays an essential role in what we are about to discuss. The quickest way to realize value in this command is to point stat at a target file and see what results.
The following is an example stat run on a file:
% stat WEB_CONTENT-Linux\ History\ Timestamps.docx 16777232 5040343 -rw-r--r-- 1 thomasmillar staff 0 3062342 "Nov 11 06:12:24 2022" "Nov 11 06:04:01 2022" "Mar 1 13:21:31 2023" "Oct 10 13:35:07 2022" 4096 5984 0 WEB_CONTENT-Linux History Timestamps.docx
There is more to stat than just the default options. The stat output can give you some super cool items in addition to the timestamps that you might already know, in particular, the file type, file size, inode, user ID, and name of the owner, to name a few. Looking at the ‘man page’ will reveal quite a bit about it.
With that in mind, a few years back, I came across an output summary for stat that I feel is very helpful for anyone in our line of work to understand what the field output represents. This can be a good reference for anyone working in the field of digital forensics / incident response (DFIR).
# Stat output Fields # %N - quoted file name # %s - File size in bytes # %b - Disk space used in 512 byte blocks # %o - optimal I/O transfer size hint # %F - file type # %D - device number in hex # %d - device number in decimal # %i - inode number # %m - mount point # %h - number of hard links # %a - access rights in octal # %A - access rights in human readable form # %C - SELinux security context string # %u - user ID of owner # %U - user name of owner # %g - group ID of owner # %G - group name of owner # %w - time of file birth, human-readable; - if unknown # %W - time of file birth, seconds since Epoch; 0 if unknown # %x - time of last access, human-readable # %X - time of last access, seconds since Epoch # %y - time of last modification, human-readable # %Y - time of last modification, seconds since Epoch # %z - time of last change, human-readable # %Z - time of last change, seconds since Epoch
Now, a question may be brewing: "How do we use this?"
Fantastic question! Let’s make this have utility value for us. The biggest appeals of Unix and Linux have to do with the tools and utilities that can do simple jobs very well and allow for interconnection with other tools. A perfect example would be to link using that venerated find command and its functions to find all the files in a file system and pass the output over to what stat can do for us.
Let's try out find this way:
find / -exec stat --format=%N\|%s\|%b\|%o\|%F\|%D\|%d\|%i\|%m\|%h\|%a\|%A\|%C\|%u\|%U\|%g\|%G\|%w\|%W\|%x\|%X\|%y\|%Y\|%z\|%Z {} \; >> stat-results.csvThat command uses find to locate every file known to the Linux OS beginning with '/' and, for each that is found, passes the file name over to stat as part of the -exec parameter, along with all the switches to govern its output.*
*Fair warning: The command will start at the top of the file system (indicated by the ‘/’ character) and go down every path, including /proc/ and mount points, and including those for file shares over Network File Sharing (NFS). Know in advance whether these or similar conditions may make your testing slow down performance on mission critical/productions systems. Consult the 'man page' on find for tips on controlling it and allowing it to skip share mounts, etc.
This will produce a listing of all the stat output fields in an output file with pipe character delimited fields. This can be super useful if we run this on everything, and it can put us on the road to achieving that file listing we discussed earlier.
Years ago, when I got started down the path of doing computer security investigations, I came across this nifty command in the book Real Digital Forensics: Computer Security and Incident Response by Keith Jones et al., 2005, https://www.amazon.com/Real-Digital-Forensics-Computer-Paperback/dp/B011DB4IAW. In essence, the command used the same find command, but passed the output to printf, which allowed for format strings to be output if specified. The command can be found on page 59, under the heading, 'File System Time and Date Stamps', and the command from the book is shown below:
find / -printf “%m;%Ax;%AT;%Tx;%TT;%Cx;%CT;%U;%G;%S p\n”
Here's what running this command reveals:
- File permissions
- Date of last access
- Date of modification
- Time of modification
- Date when the inode was changed
- Time when the inode was changed
- File user ownership
- File group ownership
- File size
- Location, with the full file path on the file system
Over my time investigating cases involving Linux systems, I have used variations of this command. In a particularly useful variation, I put that output somewhere that I can compose a body file. The body file is a file system listing that displays the activity of files within the file system. So, whenever I had to come up with a collections script for hosts some form of Unix (like the Apple macOSor Sun now Oracle Solaris platform), I would figure out how to tie together commands to produce the output I could use in the form of a body file.
Here is an example where I can simply use the printf parameter within find to produce the listing in body-file-compatible format.
find / -printf "0|%p|%i|%M|%U|%G|%s|%A@|%T@|%C@|\n" > `hostname`-bodyfile
This produces a listing of all the files within the system and labels the output file with the hostname as part of the resulting filename. This worked in most instances where the Linux OS was running on the host.
This next exhibit was derived while working IR cases involving Apple macOS, on which the -printf parameter was not an option to use, so I had to do some experimenting to find something that would work. Soon, I found that I could pass a -print0 parameter and then pipe that into the standard input of xargs, which took that input and invoked stat in a specific but familiar manner to produce a body file.
find / -print0 | xargs -0 stat -f '0|%N|%Di|%Sp|%Du|%Dg|%DZ|%a|%m|%c|%DB%n' > `hostname`-bodyfile
This produces a listing of all the files within the system and prepends the host name to the resulting filename.
Plenty of examples exist of this utilization in action, but understand that, depending on the actual operating system, you might need to try using variations of stat and find or other commands to achieve the file listing from the Linux/Unix systems on which you are working.
In closing, we understand now that Linux produces file listing output upon request, but it assumes you have the knowledge to apply the necessary parameters or pass output over to the suitable command to produce the desired output. In the continuously evolving landscape of IR, it is a big payoff to explore and try out alternatives to gather data from different operating systems. Body files provide a powerful likeness to the data from the Windows $MFT file. This gives examiners the crucial capability to understand what file activity happened so that they can use digital analysis to answer questions and make sound conclusions. By utilizing this essential artifact, Incident Responders can grow their capabilities to effectivity address the unique challenges found in Linux-based incidents.
Happy hunting!